Integrating two or more knowledge graphs involves, among other tasks, finding matches between equivalent data properties of the graphs, also called node attributes, literals, etc.

with the same shape denotes a match
The typical approach for this in existing proposals is to use unsupervised techniques based on, mainly, the similarity of the property names so that, for example, property “ISO” is matched to “ISO sens.”. This approach, however, fails when matching properties have very different names, as is typical in real world datasets. For example, property “resolution” would match property “megapixels”.
To deal with these cases, some proposals have made use of property instances and word embeddings. Property intances are known examples of the value of a property. Features can be devises to detect when such instances have a similar format for a pair of properties, such as “10 mp” and “12.2”. Word embeddings are pre-computed numeric vectors associated to known words whose values somehow correlate to the semantics of the word. These vectors can be used to compute, through vector distance methods, the semantic similarity between two property names, for example.
However, these techniques use these features in an unsupervised way, which has the advantage of not requiring training data, but makes the matching prediction rely on manual thresholds or non-intelligent use of features. For example, existing techniques that use word embeddings compute semantic similarity by computing the cosine distance between two vectors. However, this method makes each component of the vector have the same weight when computing the similarity.
LEAPME attempts to solve these problems by means of a supervised use of classical name similarity features, instance-based features, and word-embeddings features. From pairs of properties, LEAPME computes a large vector with all the aforementioned features. These are passed to a neural network that uses them in a smart way and classifies the pairs as matching or non-matching.
While LEAPME needs training data, our experiments have shown that there is potential to train a generic classifier with data from other external domains, which would enable the use of a pre-trained classifier. The following figure shows the results obtained when training with some data domains and testing with different ones:
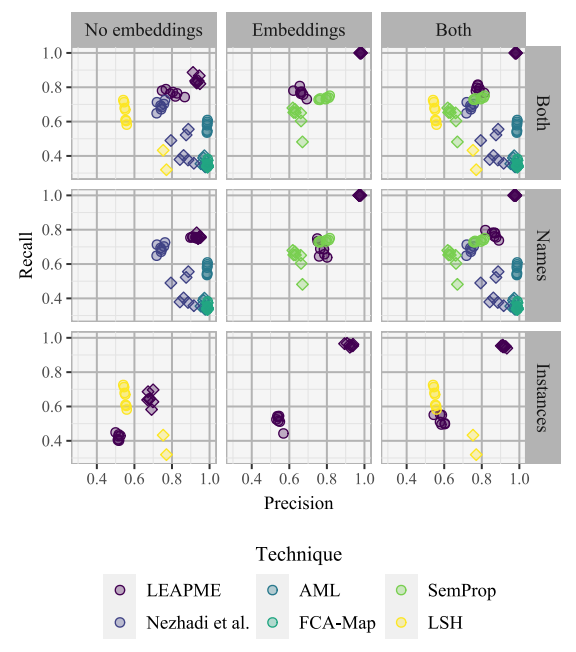
It can be observed that LEAPME’s results are excellent, mainly when embedding features are used.
Get “LEAPME” on its Github repository
Related Articles
2022
Leapme: Learning-based property matching with embeddings Journal Article
In: Data & Knowledge Engineering, vol. 137, pp. 101943, 2022, ISSN: 0169-023X.
How to use LEAPME
You can find the full documentation on LEAPME’s Gihub repository above.