Abstract
Imagine you have collected some structured information without any kind of labels indicating whate each thing is. For example:
- Canon EOS 1000
- 499€
- Canon
In order to properly use this information, we would have to label it with known classes with a program. The program could guess that element 3 (“Canon”) is the brand by having seen the same textual values in available examples of such class. It could guess that element 2 is a price because of the presence of mainly numbers and a single symbol. And it could guess that element 1 is a product name because of its longer length and occurrence of both numbers and letters.
While the former example was relavitely easy to classify, there could be more challenging cases like the following one:
- Canon EOS 1000
- 499€
- 450€
- Canon
In this case, apart form the price field there is a discounted price field. How could the program notice them and properly classify them? Their format is identical, and even the distribution of the numerical values is pretty much the same. The decisive difference, then, is not in their isolated values, but in their context. Normal prices are near something that seems to be a price, but has a lower value. Discounted prices are near something that seems to be a price, but has a higher value. This idea of finding information by taking into account what other elements in the context seem to be is what we tried to exploit with TAPON, and more precisely with its main contribution: hint-based features.
Hint-based features are features (measurements from one of the elements to be labelled) that require the existence of a preliminary set of labels indicating what each element seems to be (hints). In the former example, using traditional features, we could label both normal and discounted prices as “price”. Then, we could compute a new feature such as “difference between this element and the nearest price”, which would yield a positive value for the normal price and a negative one for the discounted price, thus adding new information that could be used to properly label in a second iteration. This iterative process that uses two models (one with traditional features and one with added hint-based features) is what characterises TAPON.
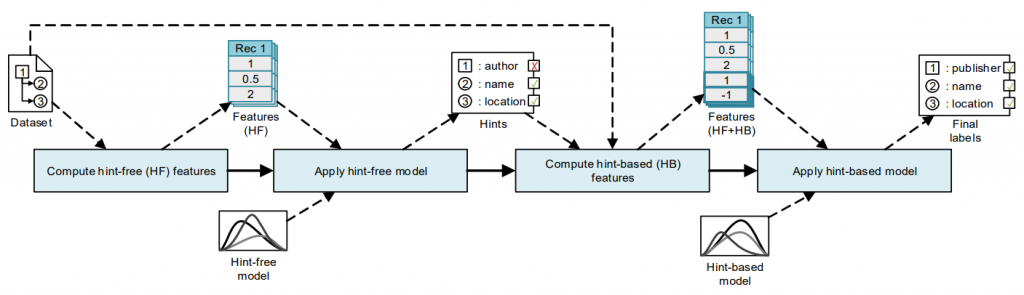
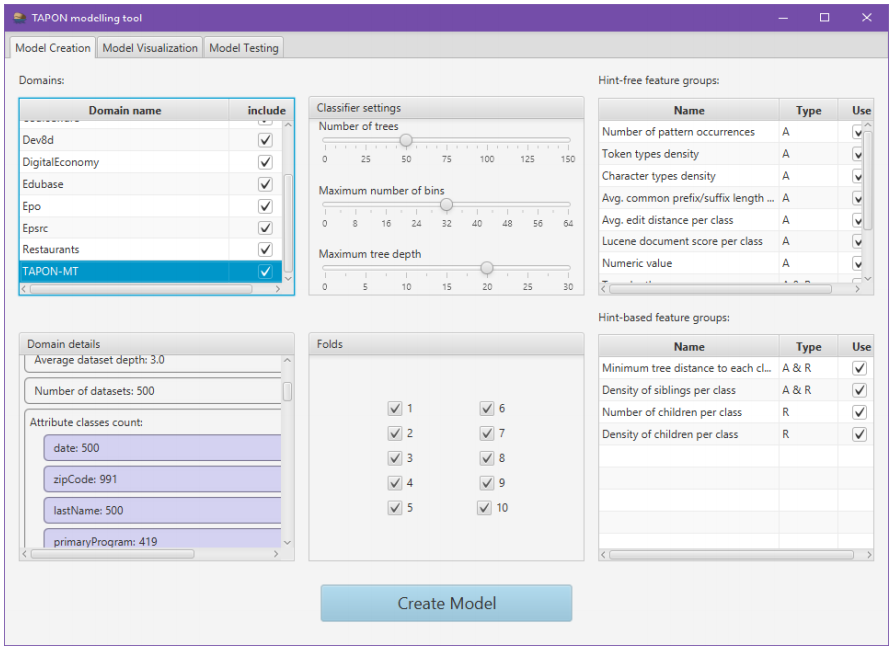
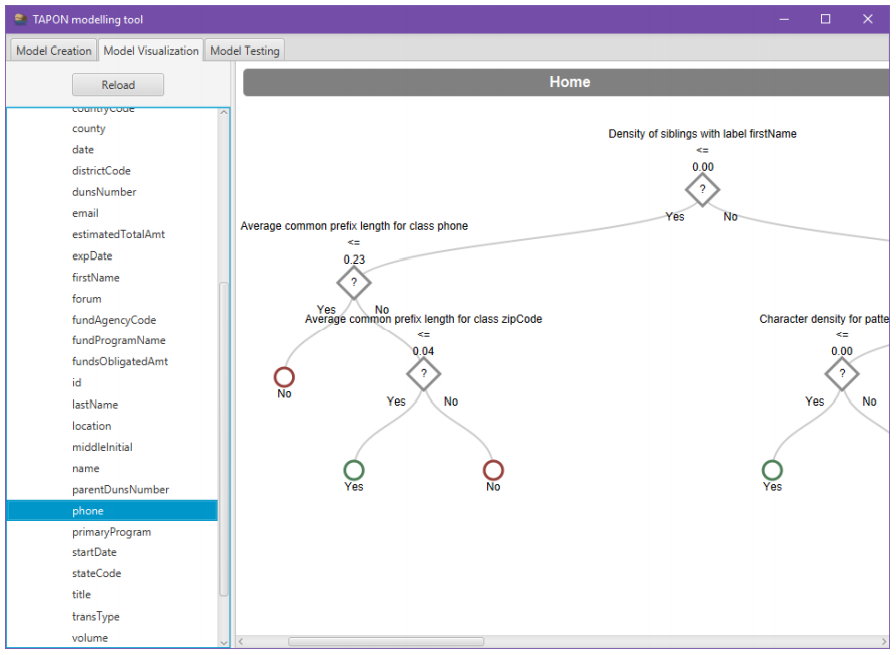
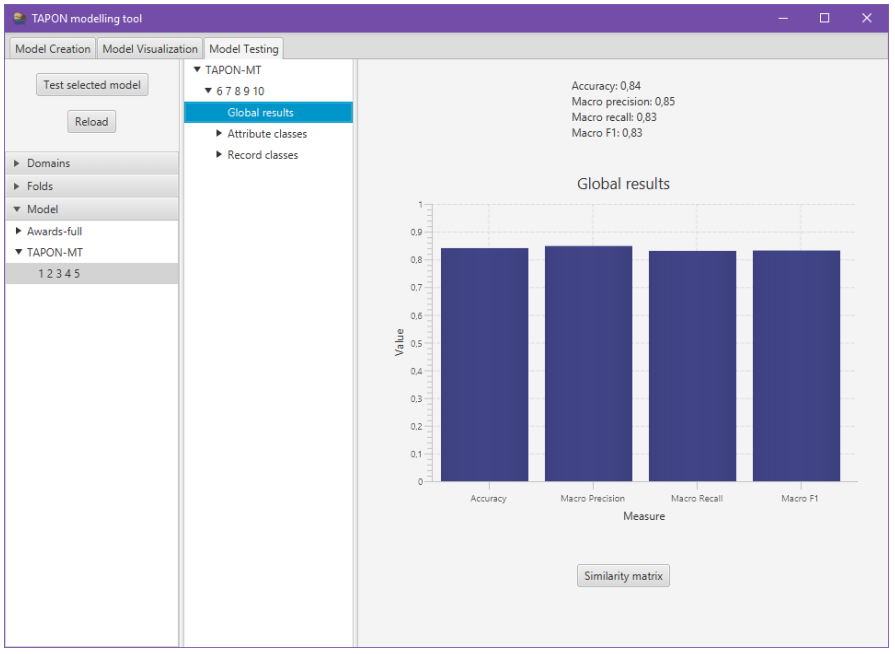
TAPON also includes a visual interface for training random forest models, visualizing them, and testing them called TAPON-MT (TAPON Modelling Tool).
Related Articles
2019
Daniel Ayala, Inma Hernández, David Ruiz, Miguel Toro. (2019).
author = {Daniel Ayala and
Inma Hernandez and
David Ruiz and
Miguel Toro},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/journals/is/AyalaHRT19.bib},
doi = {10.1016/j.is.2018.12.006},
journal = {Inf. Syst.},
pages = {57--68},
timestamp = {Fri, 27 Dec 2019 00:00:00 +0100},
title = {{TAPON-MT:} {A} versatile framework for semantic labelling},
url = {https://doi.org/10.1016/j.is.2018.12.006},
volume = {83},
year = {2019}
}
2019
author = {Daniel Ayala and
Inma Hernandez and
David Ruiz and
Miguel Toro},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/journals/kbs/AyalaHRT19.bib},
doi = {10.1016/j.knosys.2018.10.017},
journal = {Knowl. Based Syst.},
pages = {931--943},
timestamp = {Tue, 25 Feb 2020 00:00:00 +0100},
title = {{TAPON:} {A} two-phase machine learning approach for semantic labelling},
url = {https://doi.org/10.1016/j.knosys.2018.10.017},
volume = {163},
year = {2019}
}
How to use TAPON
Instrucciones aqui