
Abstract
Knowledge graph completion consists in, mainly, using some technique to guess what are the missing edges in an incomplete knowledge graph. Evaluating these techniques involves simulating this incomplete-ness by taking a knowledge graph and removing some of the edges. It is also typical to generate negative examples (edges that should not be in the graph) for training or testing the techniques. And of course, the graph can be processed beforehand to filter some relations, etc. When techniques have been applied, the evaluation metrics must be selected and computed.
Overall, KG completion evaluation involves lots of decisions that can crucially affect the perceived performance of the techniques. However, papers presenting these evaluations use heterigeneous terminology, consider different aspects when creating evaluation datasets, use different metrics, and overall make it difficult to study what things should be taken into account when preparing evaluation.
Therefore, to ease the evaluation process, we have created AYNEC (All You Need for Evaluating Completion), a set of tools for creating evaluation datasets (AYNEC-DataGen) and computing metrics from the techniques’ results (AYNEC ResTest). AYNEC defines every step in the evaluation process as well as the possible points where several options can be selected, such as the strategy for generating negative examples, or frequency thresholds for filtering relations.
Finally, AYNEC includes a set of pre-generated evaluation datasets (AYNEC-Dataset) that follow popular configurations for out of the box evaluation. These datasets, available at Zenodo, include full and reduced versions of existing popular datasets like Freebase and NELL.
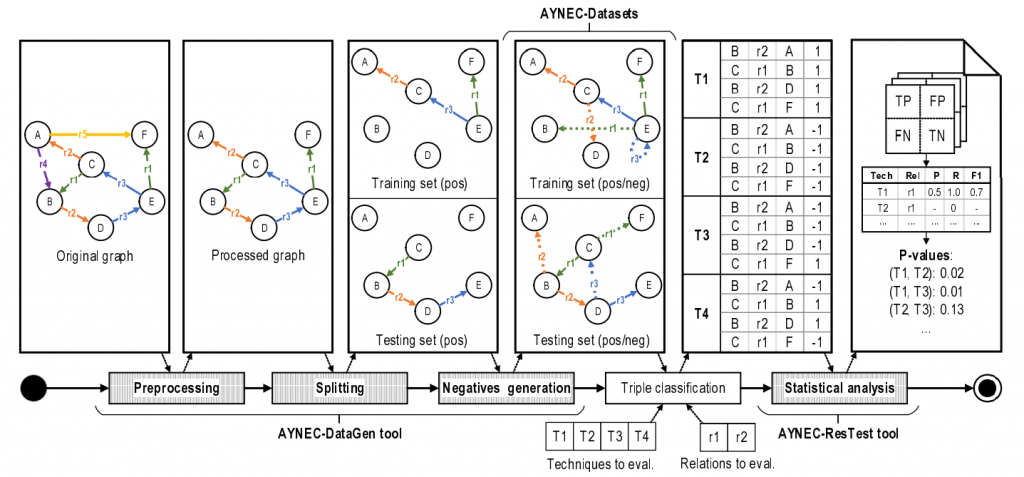
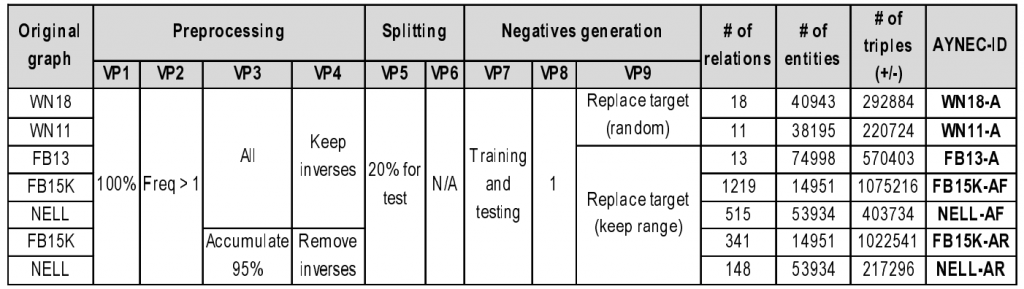
AYNEC defines a total of 9 variation points:
- VP1: Fraction of the original graph to keep.
- VP2: Relation frequency threshold.
- VP3: Relation accumulated fraction threshold.
- VP4: Inverse removal.
- VP5: Testing fraction.
- VP6: Testing fraction per relation.
- VP7: Inclusion of training negatives.
- VP8: Negatives per positive.
- VP9: Negatives generation strategy.
The following image shows how these were instantiated for AYNEC-Datasets:
Related articles
2019
author = {Daniel Ayala and
Agustin Borrego and
Inma Hernandez and
Carlos R. Rivero and
David Ruiz},
bibsource = {dblp computer science bibliography, https://dblp.org},
biburl = {https://dblp.org/rec/conf/esws/AyalaBHR019.bib},
booktitle = {The Semantic Web - 16th International Conference, {ESWC} 2019, Portoro{\v{z}},
Slovenia, June 2-6, 2019, Proceedings},
doi = {10.1007/978-3-030-21348-0\_26},
pages = {397--411},
publisher = {Springer},
series = {Lecture Notes in Computer Science},
timestamp = {Fri, 31 Jan 2020 00:00:00 +0100},
title = {{AYNEC:} All You Need for Evaluating Completion Techniques in Knowledge
Graphs},
url = {https://doi.org/10.1007/978-3-030-21348-0\_26},
volume = {11503},
year = {2019}
}
How to use AYNEC
You can view the full documentation on aynec in our github avobe.